EF and multiple result sets stored procedure
Based on MSDN article we can use .GetNextResult
I’m going to use simple database with only 2 tables: Blogs and Posts and a stored procedure that returns all blogs and all posts at once. Database schema is included in source code archive. I also use .edmx-based Database-first Entity Framework 6.1.3 for tests.
GetNextResult
In order to use this approach, you have to modify .edmx file, because automatic generation is not supported and it is theoretically possible to get this changes overwritten next time when you update model based on database schema. To use this approach, you need to invoke stored procedure and then call .GetNextResult to receive every next result. It looks typical to Entity Framework with everything hidden inside edmx and no string literals in code.
using (var db = new BloggingContextEntities())
{
// Run the sproc and read blogs from the first result set
var blogResult = db.GetAllBlogsAndPosts();
var blogs = blogResult.ToList();
// Read posts from 2nd result set
var postsResult = blogResult.GetNextResult<Post>();
var posts = postsResult.ToList();
}Translate
In this case we don’t need to modify .edmx file, in fact this approach can be used with code first and DbContext. However, you have to reference string literals in your C# code
using (var db = new BloggingContextEntities())
{
// Create a SQL command to execute the sproc
var cmd = db.Database.Connection.CreateCommand();
cmd.CommandText = "[dbo].[GetAllBlogsAndPosts]";
try
{
// Run the sproc
db.Database.Connection.Open();
var reader = cmd.ExecuteReader();
// Read blogs from the first result set
var blogs = ((IObjectContextAdapter)db).ObjectContext.Translate<EFStoredProcJit.Blog>(reader, "Blogs", MergeOption.AppendOnly);
// Read posts from 2nd result set
reader.NextResult();
var posts = ((IObjectContextAdapter)db).ObjectContext.Translate<EFStoredProcJit.Post>(reader, "Posts", MergeOption.AppendOnly);
}
finally
{
db.Database.Connection.Close();
}
}Performance tests
I used 2 test suites: execute 1000 iterations on completely empty database with no blogs and posts and then do the same on database with 5 blogs, 20 posts each.
| Method | Execution time, ms |
|---|---|
| Translate, no records | 882 |
| GetNextResult, no records | 23255 |
| Translate, 5+100 records | 3110 |
| GetNextResult, 5+100 records | 32980 |
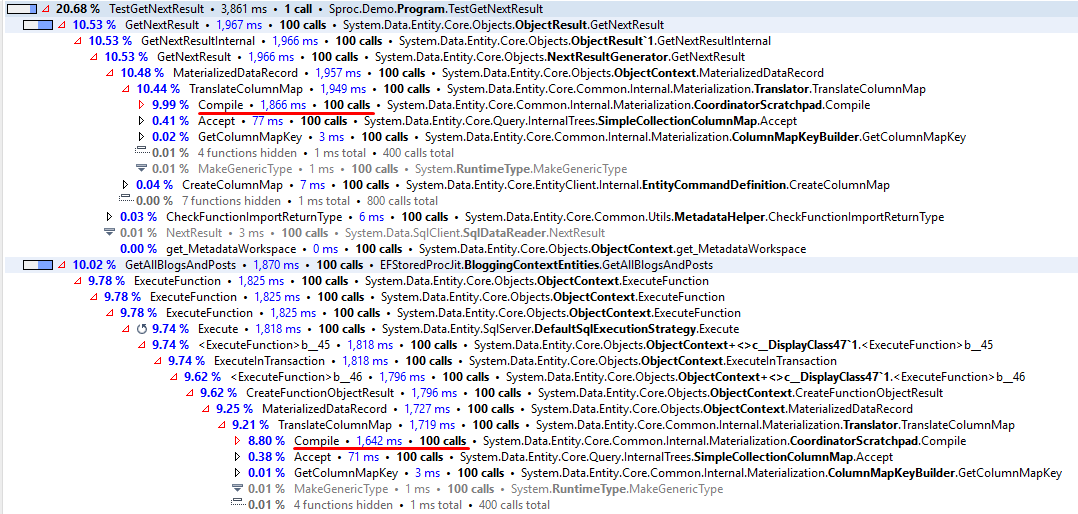
Based on results, GetNextResult has high overhead even when there are no real data returned. It turns out that GetNextResult solution does dynamic JIT compilation every time when the method is invoked (Profiler screenshot). In contrast, Translate method do not cause extra compilation and works much faster.
{kind=link}
Conclusion
GetNextResult-based solution works slower and requires manual .edmx file manipulations to work successfully. It has an advantage of more compact code and do not use database object names as string literals in code. Overall I decided to switch to Translate solution everywhere when I used GetNextResult.
Test solution source code and database schema can be downloaded here